Since the release of ChatGPT in November 2022, there has been an explosion of interest in Generative AI (GenAI). There have been several factors that have contributed to the proliferation and popularity of GenAI models. These include datasets that are greater in both quality and quantity, the development of more powerful computers and the open-source culture.CategoriesMachine Learning, Artificial Intelligence
Date Published
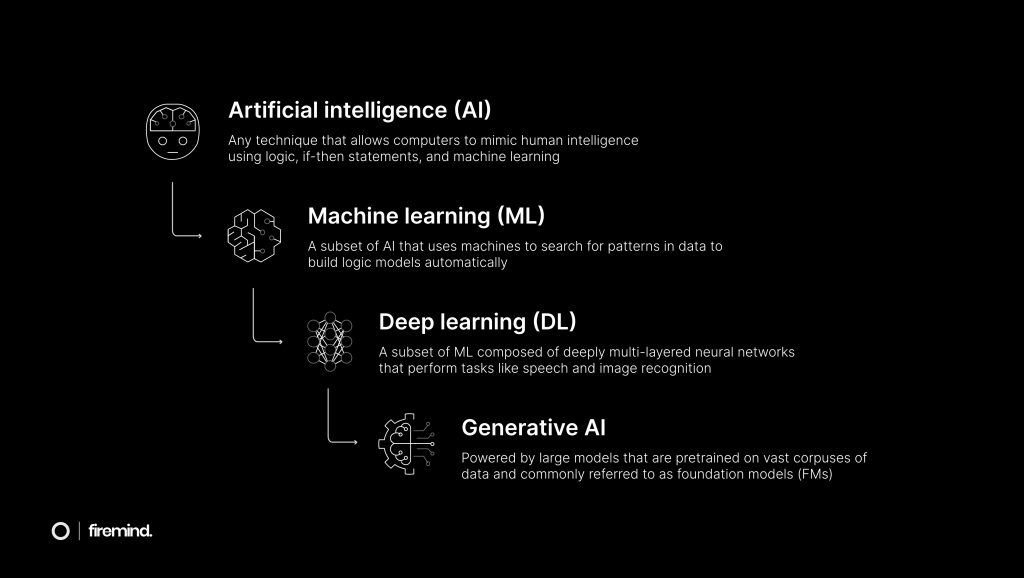
Deep Learning, The Transformer And The Rise In Generative AI
The fundamental driver behind the growth of GenAI is the development of deep learning (DL). DL is a subset of machine learning (ML), where models are capable of learning the non-linear patterns that exist in many real-world datasets. More conventional ML algorithms are well-suited to making predictions on linear data where the objective is more specific, or “narrow”. However, these algorithms perform poorly when faced with more complex non-linear datasets. Many natural language processing tasks – such as sentiment analysis, machine translation, and text generation – make use of non-linear data. DL has proved very effective in capturing these non-linear relationships.
A relatively recent breakthrough in DL was the advent of the Transformer architecture, published in 2017 by Vaswani et al. (Google Brain). The majority of today’s state-of-the-art GenAI models make use of the Transformer, including ChatGPT – hence Generative Pre-trained Transformer. It is credit to the industry’s open-source culture that Google research has enabled the progress of a company that is arguably its rival – in January 2023 Microsoft invested $10 billion in OpenAI, ChatGPT’s parent company.

Prior to the Transformer, recurrent neural networks (RNNs) were the go-to for tasks that made use of sequential data such as text. However, one limitation of RNNs is their inability to learn long-range dependencies. Long-range dependencies refer to the relationships between entities in a sequence that are far apart from each other (“sequence” and “sentence” will henceforth be used interchangeably). Consider the following sentence as an example: “Though the cat was frightened by the sudden noise, it eventually ventured out from under the bed and cautiously explored the room.” Here, “it” refers to “the cat” mentioned at the start of the sentence. The fact that these two phrases are related to each other but do not appear one after another (sequentially) – they are separated by several intervening words – means that they represent a long-range dependency.
RNNs can fail to learn long-range dependencies because they rely on an approach that processes data sequentially, i.e. one word after another. This approach can lead to the vanishing gradient problem, where the effect of input data that has occurred earlier in the sequence can have a diminishing effect on the output, or the next predicted word. Consider the following sentence: “Louis, who moved to the United States from France at the age of 10, speaks fluent English with a hint of an accent.” In order for a model to learn why Louis has an accent when speaking English, it must “remember” his French origins that are mentioned earlier in the sentence. RNNs might “forget” earlier information in a sequence that gives contextual relevance to information that appears later in the sequence. Indeed, they are more prone to “forgetting” such information when the sequence is longer. So when there are more intervening words between the mention of Louis’ French origins and the mention of his accent, a RNN is less likely to “understand” why Louis has an accent.
The vanishing gradient problem occurs due to the nature of backpropagation. On a high level, backpropagation is an algorithm used to update the parameters of a model in order to improve its accuracy. Backpropagation works backwards, updating the model’s parameters with respect to the effect of the previous elements on the parameters. So given the sentence about Louis and his accent, the effect of “moved” – the third word – on the model’s parameters would also consider the effect of both the first and second words: “Louis” and “who”. The vanishing gradient problem occurs when the effect of earlier words in the sentence becomes increasingly small. In the same example sentence, “Louis” – the first word – would have the least significant effect on the model’s parameters. This is clearly a problem because the meaning of “Louis” on the rest of the sentence is highly significant.
While there have been variants of RNNs such as long short-term memory and gated recurrent unit that have helped diminish the effect of the vanishing gradient problem, these approaches continue to rely on the sequential processing of data. With the inception of the Transformer, a new approach of processing data in parallel was released. This means that, for example, all words in a sentence are processed simultaneously. This approach helps to overcome the vanishing gradient problem and thus to help the model learn long-range dependencies. The ability of the Transformer to process data in parallel is because of the architecture’s main innovation – the attention mechanism. The idea behind this mechanism is to allow the model to focus on certain parts of the input when generating an output, which is achieved by assigning different levels of attention to different parts of the input.

The vanishing gradient problem occurs due to the nature of backpropagation. On a high level, backpropagation is an algorithm used to update the parameters of a model in order to improve its accuracy. Backpropagation works backwards, updating the model’s parameters with respect to the effect of the previous elements on the parameters. So given the sentence about Louis and his accent, the effect of “moved” – the third word – on the model’s parameters would also consider the effect of both the first and second words: “Louis” and “who”. The vanishing gradient problem occurs when the effect of earlier words in the sentence becomes increasingly small. In the same example sentence, “Louis” – the first word – would have the least significant effect on the model’s parameters. This is clearly a problem because the meaning of “Louis” on the rest of the sentence is highly significant.
While there have been variants of RNNs such as long short-term memory and gated recurrent unit that have helped diminish the effect of the vanishing gradient problem, these approaches continue to rely on the sequential processing of data. With the inception of the Transformer, a new approach of processing data in parallel was released. This means that all words in a sentence are processed simultaneously. This approach helps to overcome the vanishing gradient problem and thus to help the model learn long-range dependencies. The ability of the Transformer to process data in parallel is because of the architecture’s main innovation – the attention mechanism. The idea behind this mechanism is to allow the model to focus on certain parts of the input when generating an output, which is achieved by assigning different levels of attention to different parts of the input.
Before exploring the attention mechanism, it is useful to understand the significance of word embeddings in enabling a model to “understand” the semantic meaning of words. Embeddings convert words into numerical vectors, e.g. “queen” = [1.2, 0.8, 0.5]. In practice, however, each word will have not just three but hundreds of dimensions. A high-dimensional vector representation of a word enables a deep “understanding” of the meaning of that word with regards to other words. Word2Vec (word to vector) is a popular approach used for word embeddings. It learns embeddings with respect to words that surround it, i.e. it learns context. The values of a vector’s dimensions are latent features, meaning that they are learned from the data and are not directly interpretable. Given the example of “queen”, this means that we cannot give its three dimensions three definitive representations, e.g. 1.2 = “royalty”, 0.8 = “female” and 0.5 = “power”. Instead, these abstract dimensions represent the similarity or difference between one word and another. So, a model such as Word2Vec is likely to find that the difference between the vectors for “queen” and “king” is very small, i.e. that these words are used in similar contexts and thus that these words have a similar meaning. The accuracy of these vector representations will of course be greater if the embeddings model is trained on a corpus of words that is both larger and more varied. Without embeddings, language models would have no inherent knowledge of the meaning of a given word and so would not be able to perform natural language understanding and generation.
The attention mechanism is no exception, it uses embeddings to give meaning to the words it processes. The first step of the mechanism is to calculate attention scores which represent the importance of each input word with respect to the output word that is being generated. Take, for example, the following sentence: “The cat sat on the…” where the model is trying to predict the next word. Assume that the query is the embedding of the last word, “the”. The query represents the current word that is being processed by the model, and the keys are the embeddings of the preceding words, i.e. “The”, “cat”, “sat”, “on”. The model calculates a similarity score between the query and the keys. It calculates this score with a method known as dot-product. For the sake of simplicity, assume that the embeddings for these words have just a single dimension: {“The”: 0.5, “cat”: 0.9, “sat”: 0.1, “on”: 0.2, “the”: 0.7}. The embeddings of the keys are then each multiplied by the embedding of the query (0.7), giving the following attention scores: {“The”: 0.35, “cat”: 0.63, “sat”: 0.07, “on”: 0.14}. Where there are a very high number of dimensions, it is useful to scale down the scores by dividing them by the square root of the number of dimensions – this variation is known as scaled dot-product.
The next step is to normalise the attention scores using a function such as softmax. First, sum the attention scores: 0.35 + 0.63 + 0.07 + 0.14 = 1.19. Next divide each score by the sum (1.19), giving: {“The”: 0.29, “cat”: 0.53, “sat”: 0.06, “on”: 0.12}; together these normalised scores sum to 1. Normalisation is an important step because it scales the scores to ensure they represent a probability distribution. In some cases, certain dimensions will have absolute (non-normalised) values that are significantly higher than the values of other dimensions. But this difference does not necessarily mean that the dimensions with greater values are more important. The normalised attention scores represent the importance of each key in predicting the next word after the value. So in this case, “cat” (0.53) has the most relevance in predicting the next word in the sentence.
This is a simplified explanation of the attention mechanism’s ability to process data in parallel and thus to overcome the vanishing gradient problem, and to learn long-range dependencies. The parallel processing that is enabled by the attention mechanism is, in turn, enabled by powerful processors. AWS is a key player in this space, in April 2023 it released hardware designed specifically for GenAI models. Inferentia2 is a powerful instance type purpose-built for GenAI and Trainium is an accelerator designed for training DL models with over 100 billion parameters. This processing power is both easy to use through the AWS Console and available at a low-cost. Also in April AWS announced Amazon Bedrock, a service that makes the most popular open-source foundational models (FMs) from AI21 Labs, Anthropic, Stability AI and others easily accessible through an API. Bedrock will also give access to AWS’ own FMs, namely Titan Text and Titan Embeddings – two new LLMs.
Let’s explore the power of Generative AI and the Transformer with Firemind’s MLOps Platform.
Together, we identify and leverage the potential of Generative AI and Transformers in your machine learning workflows with the introduction of Firemind’s MLOps Platform.
With our MLOps Platform Toolkit, using 100% AWS native services, you can witness quick integration of Generative AI into your existing machine learning pipelines following best practices. This will enable your business to access stunning visual content, generate natural language and enhance data synthesis processes.
Finally a quick shout out to Khalil Adib for inspiration for the post and help in getting my head around the vanishing gradient problem!
Want to find out more?
Got questions? We’ve got answers! Find out how our team uses GenAI within our ML/AI projects today.


Latest Insights

Encoders, Decoders and Their Model Relationship Within Generative AI
Heard the term “Generative AI” mentioned a lot? But unsure what Generative AI actually is? How it operates? What makes it tick? In today's post,…

The Who, What, And Why of Large Language Models
In the ever-evolving landscape of artificial intelligence, large language models (LLMs) stand as a monumental advancement, poised to redefine how we…
Khalil Adib Explores Amazon SageMaker and YOLOv5 for Object Detection and Tracking
Meet Khalil Adib, one of Firemind's Data Scientists, with a passion for artificial intelligence (AI) and machine learning (ML). Customer projects…
Want to find out more?
Got questions? We’ve got answers! Find out more about our data culture, company vision and our growing team.